MySQLのオンラインDDLでDeadlockエラーになるケース
これは、MySQL Advent Calendar 2022 の7日目の記事です。
昨日は taka_yuki_04 さんでした。 next4us-ti.hatenablog.com
MySQL 5.6からオンラインDDLがサポートされ、DDL実行中でもデータの読み書きが可能ですが、DDL実行中にトランザクションの状況によってはDeadlockエラーが発生するケースがありますので、それを紹介したいと思います。
データの準備
検証に使った環境はMySQL 8.0.30です。検証用のテーブルとデータを作成します。
> select @@version; +-----------+ | @@version | +-----------+ | 8.0.30 | +-----------+ 1 row in set (0.00 sec)
>SELECT @@GLOBAL.transaction_isolation, @@transaction_isolation; +--------------------------------+-------------------------+ | @@GLOBAL.transaction_isolation | @@transaction_isolation | +--------------------------------+-------------------------+ | REPEATABLE-READ | REPEATABLE-READ | +--------------------------------+-------------------------+ 1 row in set (0.00 sec)
(MySQL5.6やisolation levelをREAD-COMMITTEDにしても結果は同じです)
CREATE TABLE user ( id bigint(20) NOT NULL AUTO_INCREMENT, name varchar(10), PRIMARY KEY (id) ) ENGINE=InnoDB;
INSERT INTO user (name) VALUES('a');
SELECT * FROM user; +----+------+ | id | name | +----+------+ | 1 | a | +----+------+ 1 row in set (0.01 sec)
Deadlockエラーの検証
-- tx1 BEGIN; SELECT id FROM user WHERE id = 1;
一つのセッション(tx1)でトランザクションを開始し検索を実行します。 検索が終わったことを確認したあとに異なるセッション(tx2)で下記を実行します。
-- tx2 ALTER TABLE user ADD INDEX index_name (name);
このインデックス作成のSQLはWaiting for table metadata lockという状態で1つ目のセッション(tx1)が終わるまでDDLが実行されずに待たされます。
コレも嫌な動作の一つですが、この記事の本題ではありません。(参考 )
次にトランザクション実行中だった1つ目のセッションで更新処理を行うとDeadlockエラーが発生します。
-- tx1 UPDATE user SET name = 'b' WHERE id = 1; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
エラーになった直後にWaiting for table metadata lockが解除されてインデックス作成が成功します。
-- tx2 ALTER TABLE user ADD INDEX index_name (name); Query OK, 0 rows affected (46.89 sec) Records: 0 Duplicates: 0 Warnings: 0
userテーブルのレコードは1つ目のセッションでしか操作していないにも関わらずDeadlockが発生しました。
DDL実行時間が長い場合にエラーになるタイミング
次は先にDDLを実行していて、DDL実行に時間がかかる場合はどのタイミングでDeadlockが起きるでしょうか?
-- tx1 ALTER TABLE user ADD INDEX index_name (name);
オンラインDDLですのでDDL実行中でも下記のようなSQLは成功します。
-- tx2 BEGIN; SELECT id FROM user WHERE id = 1; UPDATE user SET name = 'b' WHERE id = 1; COMMIT;
DDL実行中に下記のSELECTが終わったあとにDDLの実行が完了したとします。
-- tx3 BEGIN; SELECT id FROM user WHERE id = 1;
DDL完了後にこのトランザクションで更新処理をするとDeadlockが発生します。
-- tx3 UPDATE user SET name = 'b' WHERE id = 1;
DDLの実行が完了するタイミングでDeadlockが発生します。
アプリケーションで試す
アプリケーションでこの問題が発生するかを試すために下記のような簡単なスクリプトを作りました。 インデックスの作成・削除を繰り返すプログラムです。
require "bundler/inline" gemfile(true) do gem "activerecord", require: "active_record" gem "mysql2" end ActiveRecord::Base.establish_connection ActiveRecord::Base.logger = Logger.new(STDOUT) while true ActiveRecord::Base.connection.execute("ALTER TABLE user ADD INDEX index_name (name)") sleep 0.5 ActiveRecord::Base.connection.execute("ALTER TABLE user DROP INDEX index_name") sleep 0.5 end
ddl.rbという名前で保存して下記のように実行します。
DATABASE_URL="mysql2://your_user:your_password@127.0.0.1:3306/your_db" ruby ddl.rb
上記を実行しながらアプリケーションに負荷をかけてDeadlockが発生するか試すことができます。
まとめ
- オンラインDDLなので安全だと思っていたインデックス作成でもDeadlockが発生するケースがありました。
- 今回はインデックス作成のDDLを使いましたが、カラム追加などのオンラインDDLでも同じようにエラーが発生します。
- MySQLのDeadlockというエラーメッセージですが、デッドロックエラーで思い浮かぶ「2つ以上のトランザクションがお互いにロックを取り合ってエラーになる」のとは異なるケースでもDeadlockが発生するケースがいくつかあり、これもその一つです。
- 今回はすぐに試せるように少ないデータ量で発生することを説明しました。
- データ量が少なくDDLの実行時間が短くてもエラーが発生しますので、一概にすぐ終わるインデックス作成は安全とは言えないことがわかります。
- 実行時間の長いDDLの場合はDDLが終わるタイミングでDeadlockエラーが起きることがあります。
- アプリケーションでDeadlockエラーが発生したときにリトライするなどの対応が必要になります。
- 自分のアプリケーションで発生するのか是非スクリプトを実行して試してみてください。
ISUCON8本選は6位でした
本選で戦ってきました


結果は6位 13,281点

悔しい負け
今年こそは優勝したい!と思っていましたが結果は惨敗でした。マジで悔しいです。
予選の感じで3人がそれぞれの力を出せれば優勝はできそうだなという感触があったし、songmuさん、najeiraさんという超強力なメンバーで本選だったので今年こそは何としてもと思っていましたが、結果は力及ばずでした。
講評や懇親会で話を聞くとISULOGGERの/send_bulkに気付いていなかった為にどんなに改善しても頭打ちだったとのこと。RunTradeやInfoのローソク足チャートを表示するGetCandlestickDataの改善は対応していたのにログで頭打ちなのでスコアは伸びずで悔しい結果になってしまった。(懇親会で話した感じではおそらく/send_bulkになっていれば3.5万は超えた気がする)
マニュアルをちゃんと読んでいれば/send_bulkに気付けたはずなのに、なんかボリューム多そう、Dockerかーとか思ってしまったばっかりに早く手を動かなさなきゃという気持ちでいっぱいで私はマニュアルを流し読みしてしまった。この辺りは力不足ですぐに構成を把握することができればそんなにテンパらなかったと思う。あと、429: Too Many Requestsのログが出ていてもすぐにピンと来なかったのは単純に力不足。その時はん〜なんだろうとしか思えなかった。。。今マニュアルを見返すと制限とかもきっちり書かれてるしー。
今回の問題はボトルネックがわかっても私はいまいち改善策が思い浮かばず、結構な時間を悩んでいるだけで消費してしまった。
RunTradeの改善方法に私は突破口が見いだせなかったのでsongmuさん、najeiraさんに完全にお任せし、私の得意なDB検索問題であるInfoのローソク足チャートを表示するGetCandlestickDataの改善をした。結果的には私はこれくらいしか効果的な改善ができなかった。
GetCandlestickDataの改善
問題のSQLは下記
SELECT m.t, a.price, b.price, m.h, m.l FROM ( SELECT STR_TO_DATE(DATE_FORMAT(created_at, '%s'), '%s') AS t, MIN(id) AS min_id, MAX(id) AS max_id, MAX(price) AS h, MIN(price) AS l FROM trade WHERE created_at >= ? GROUP BY t ) m JOIN trade a ON a.id = m.min_id JOIN trade b ON b.id = m.max_id ORDER BY m.t
次のような結果のテーブルを作成し
CREATE TABLE IF NOT EXISTS trade_stat ( id INTEGER UNSIGNED PRIMARY KEY AUTO_INCREMENT, created_at DATETIME(6) NOT NULL, first_price INTEGER UNSIGNED , last_price INTEGER UNSIGNED , low_price INTEGER UNSIGNED NOT NULL, high_price INTEGER UNSIGNED NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
下記のSQLに変更した
SELECT STR_TO_DATE(DATE_FORMAT(created_at, '%s'), '%s') AS t, MIN(first_price), MAX(last_price), MAX(high_price) AS h, MIN(low_price) AS l FROM trade_stat WHERE created_at >= ? GROUP BY t ORDER BY t
これも最初仕様を勘違いしてしまっていて1時間くらい無駄にしてしまった。もっと早く入れれていればログに気付くきっかけがあったかも知れなかった。
ISUCON8の運営チームは最高でした
予選、本選ともにトラブルはなかったし、ベンチマークもサクサクで快適でした。問題はどちらも様々なボトルネックが作り込まれているのと負荷に耐えれるとアクセス数がどんどん増えるというのがスムーズで納得感のある動きでした。シェア機能はすごく面白いギミックでした。
準備が本当に大変だったと思うのですが、ありがとうございました。
メンバーに感謝
songmuさん、najeiraさんと一緒に戦えてよかった。二人ともめっちゃ強いので足引っ張るわけにはいかないなーと思っていた。本選では私は気付いていなかった点を二人は気付いてて懇親会ではあー実はそうだったんだーと言うような話も多くて力の差を感じた。go慣れしていないというのもあるけど、視野や発想が私よりだいぶ上だなと感じたので精進しないと。
楽しい良い経験をさせてもらいました。ありがとう。
ISUCON8予選突破しました
予選突破
ISUCONというWebアプリケーションのパフォーマンス改善コンテストに参加し、予選突破しました。去年は不参加だったので2年振り2度目。(blog書くのもISUCON6振りで2年振りという... output無さすぎ)
いやー実に楽しかった。やっぱりISUCONでしか味わえないモノがある。いつも何か新しい学びがある。
予選は両日共に問題なく進んだようですし、予選問題もいい問題でした。ベンチマーカーが詰まることもなく快適な予選でした。運営のみなさんありがとうございます。
久しぶりの参加だったので事前にISUCON7予選を解いてみたりconoha vpsでサーバ立ててansibleやfabric(deployに使っている)の動作確認をしたりして挑みました。ISUCON7予選を動かし始めたらあーこの感じやっぱり楽しいなと思って気持ちを高めてISUCON8に臨めて良かった。何を事前準備しないとイケないのかの確認もできたので予習大事ですね。
チーム:死闘の果てに
@najeiraとまた出ようって話はしてたけど、もう一人のメンバーが見つからずダメ元でTwitterで募集する。



マジで@songmuさん来てくれんの!?ってことでめっちゃテンション上がりました。
予選の結果は528組中7位
予選は528組(一般 432、学生96 [1,392名])中 7位でした。

- 学生3チームも上位3チームに入ってるの本当に凄い
http://isucon.net/archives/cat_1024995.html
最終スコア

スコアの推移が記録できていないので何を変更したら何点行ったのかイマイチわからず。途中はベンチマーク結果がランダムに成功したり失敗したりの繰り返しで安定せず、スコアが出れば2万みたいな状態が続きました。
najeiraがアプリを改善し常に成功するようになったところで、後に記載する予約済みテーブルの対応を入れたところ3.8万が出て再実行しても失敗しないか確認の為に2回追加で実行したらスコアが上がって4.5万で終わり。まだ時間はあったのでsongmuさんのRedis対応を入れたかったが予選通過の可能性があったので安全のためにもうベンチマーカーを実行するのをやめて終了。
Redis実装入ったら何点だったのか見たかったーー。毎回思うけど時間切れ後に最後にこの実装入れたら何点になっていたのかって知りたい。
予選問題
チケット販売システム。席を予約するので排他制御が必要でMySQLのロックが含まれる問題でした。
サーバはCentOS7 3台で最初は1台にAppとMariaDBが入っている構成でスタート。
予選でやったこと
ざっと変更点を箇条書き(私以外のところは私の把握してる範囲のみ)
- songmu
- validateRankのselect count from sheetsを無くす
- reservetions#last_updated_atのカラムを追加して
ORDER BY IFNULL(r.canceled_at, r.reserved_at) DESC LIMIT 5をORDER BY last_updated_at DESC LIMIT 5で済むようにする - Redisで空き座席を管理するようにしてMySQLでFOR UPDATEしているactions/reserveを高速化(これは間に合わず断念)
- najeira
- getEvents/getEventでevent_id INにするなどしてSQL発行回数を減らす
- h2oをnginxに変更
- DBサーバ、Webサーバ、Redisサーバの3台構成にする
- bluerabbit
- 計測/分析
- reservetionsにINDEX追加
- 予約済みテーブルを追加しreservetionsをreadしてるSQLを高速化
予選でやらなかったこと
- Webサーバー複数台
- getEventなどの検索結果のキャッシュ
- DBのチューニング
- goライブラリの変更
- Viewレイヤーの変更
- MySQLのFOR UPDATEの処理変更
作業分担
私は普段goは書かないので前半は計測やINDEX作成などの裏方作業をしてgoは得意な二人に任せることにした。
後に記載する計測結果でgetEventと座席の排他制御がキモだと判断し、getEventのN+1 Queryを@najeira、Redisで空き座席を管理する一番難しいところを@songmuという担当になった。
事前の打ち合わせは数日前に1時間ほど話をした程度だったがスムーズに担当割できた。
以下は私がやったことと計測の仕方や対応した内容を書く
各テーブルのレコード数を確認する
まず最初に初期実装のベンチマークを実行した後のレコード件数を記録する
select count(*) from administrators -- 101 select count(*) from events -- 20 select count(*) from reservations -- 191847 select count(*) from sheets -- 1000 select count(*) from users -- 5012
ベンチマーク実行前の件数は取得し忘れたが、実行前後で見比べてレコード数に変化があるテーブルと変化の無いテーブルを確認する。変化の無いテーブルはキャッシュするなどの対象になるが今回はキャッシュはしなかった。
各メソッドとendpointの実行回数を計測する
najeiraとISUCONに出る時はいつもコレで計測する
https://github.com/najeira/measure を使って各メソッドとendpointの実行回数と時間を計測する
func getEvent(eventID, loginUserID int64) (*Event, error) { defer measure.Start("getEvent").Stop()
- 各メソッドで計測コードを入れる
e.POST("/api/events/:id/actions/reserve", func(c echo.Context) error { defer measure.Start("POST_/api/events/:id/actions/reserve").Stop()
- 各endpointで計測コードを入れる
e.GET("/stats", getStatsHandler) e.GET("/stats_reset", resetStatsHandler)
初期実装の計測
measureの埋め込みが終わったらベンチマークを実行した後に/statsの結果をGoogle SpreadSheetに貼り付けてチームメンバーに共有する。多く実行されていて遅いメソッドを上から順に対応していく

ざっと大雑把にでも読み解くと
- getEventが一番問題がありそう
- /api/users/:idは内部でgetEventを呼び出しているから遅い
- getEventとgetEventsが問題ありそう
- 次に問題になりそうなpathはactions/reserveだと推測できる
という形でコレだけで対応しないとイケなそうな場所がわかる。計測結果の上位に無い処理はどんなに気になっても手を入れないし、深く調べもしないと切り分けられるのが大事。ボトルネックにだけ集中する。 コレ以外ではdstatやpt-query-digestなどを気になった時に使う形。
アプリはgoが得意な二人に任せる
全てのSQLを書き出す
次はDBに必要なINDEXを付与する。機械的にSQLをとりあえず書き出す。 思考内容も参考までに書いてみる
SELECT id, nickname FROM users WHERE id = ?
SELECT id, nickname FROM administrators WHERE id = ?
SELECT * FROM events ORDER BY id ASC
SELECT * FROM events WHERE id = ?
SELECT * FROM sheets ORDER BY `rank`, num
- rank, numにindexはあるのかな?
SELECT * FROM reservations WHERE event_id = ? AND sheet_id = ? AND canceled_at IS NULL GROUP BY event_id, sheet_id HAVING reserved_at = MIN(reserved_at)
- event_id, sheet_id, canceled_at に複合INDEXかなー
- でもGROUP BYした結果セットが多いと
HAVING reserved_atがめちゃ遅くなるなー
SELECT COUNT(*) FROM sheets WHERE `rank` = ?
- rankにindexはあるのかな?
SELECT * FROM users WHERE login_name = ?
- login_nameにindexはあるのかな?
INSERT INTO users (login_name, pass_hash, nickname) VALUES (?, SHA2(?, 256), ?)
- SHA2関数かでもSQLの関数はあんまり遅くなった記憶は無いから一旦無視かな
SELECT id, nickname FROM users WHERE id = ?
SELECT r.*, s.rank AS sheet_rank, s.num AS sheet_num FROM reservations r INNER JOIN sheets s ON s.id = r.sheet_id WHERE r.user_id = ? ORDER BY IFNULL(r.canceled_at, r.reserved_at) DESC LIMIT 5
- user_id, sheet_idの複合INDEX使っても結果が多かったらORDER BYがだいぶ辛いし、LIMIT 5かー
- IFNULL(r.canceled_at, r.reserved_at) はどうにかできないのかなー
SELECT IFNULL(SUM(e.price + s.price), 0) FROM reservations r INNER JOIN sheets s ON s.id = r.sheet_id INNER JOIN events e ON e.id = r.event_id WHERE r.user_id = ? AND r.canceled_at IS NULL
- user_id, canceled_at, sheet_idの複合INDEXかな
SELECT event_id FROM reservations WHERE user_id = ? GROUP BY event_id ORDER BY MAX(IFNULL(canceled_at, reserved_at)) DESC LIMIT 5
- またIFNULL(canceled_at, reserved_at)か
- user_id, event_idの複合はINDEXは必要だなー
SELECT * FROM users WHERE login_name = ?"
SELECT SHA2(?, 256)
- SQLでやらなくて良さそう計測結果が問題だったら対応かな
SELECT * FROM sheets WHERE id NOT IN ( SELECT sheet_id FROM reservations WHERE event_id = ? AND canceled_at IS NULL FOR UPDATE ) AND `rank` = ? ORDER BY RAND() LIMIT 1
- FOR UPDATE!!!
- ORDER BY RAND()も怪しい
- event_id, canceled_atの複合INDEXかな
INSERT INTO reservations (event_id, sheet_id, user_id, reserved_at) VALUES (?, ?, ?, ?)
SELECT * FROM sheets WHERE `rank` = ? AND num = ?
- rank, numはINDEX必要なのかなー
SELECT * FROM reservations WHERE event_id = ? AND sheet_id = ? AND canceled_at IS NULL GROUP BY event_id HAVING reserved_at = MIN(reserved_at) FOR UPDATE
- event_id, sheet_id, canceled_atの複合INDEXかな
UPDATE reservations SET canceled_at = ? WHERE id = ?
SELECT * FROM administrators WHERE login_name = ?
SELECT SHA2(?, 256)
INSERT INTO events (title, public_fg, closed_fg, price) VALUES (?, ?, 0, ?)
UPDATE events SET public_fg = ?, closed_fg = ? WHERE id = ?
SELECT r.*, s.rank AS sheet_rank, s.num AS sheet_num, s.price AS sheet_price, e.price AS event_price FROM reservations r INNER JOIN sheets s ON s.id = r.sheet_id INNER JOIN events e ON e.id = r.event_id WHERE r.event_id = ? ORDER BY reserved_at ASC FOR UPDATE
- MySQLでJOINしてFOR UPDATEはJOIN対象もロックかかるから範囲広いなー
- event_id, sheet_id, reserved_atの複合INDEXかな
select r.*, s.rank as sheet_rank, s.num as sheet_num, s.price as sheet_price, e.id as event_id, e.price as event_price from reservations r inner join sheets s on s.id = r.sheet_id inner join events e on e.id = r.event_id order by reserved_at asc for update
などSQLをざっと眺めて必要そうなINDEXを追加

予約済みテーブルを作成する
次のようなキャンセルしていない(予約済み)レコードを検索するSQLが多かった。
FROM reservations WHERE event_id = ? AND sheet_id = ? AND canceled_at IS NULL
下記を実行すると全体の19万件中の1.5万件ほどしか存在しない事がわかる。
select count(*) from reservations where canceled_at IS NULL -- 15000
次のようなテーブルを作った(sheetsはseatsの間違いw)
CREATE TABLE IF NOT EXISTS reserved_sheets ( id INTEGER UNSIGNED PRIMARY KEY AUTO_INCREMENT, reservation_id INTEGER UNSIGNED NOT NULL, event_id INTEGER UNSIGNED NOT NULL, sheet_id INTEGER UNSIGNED NOT NULL, user_id INTEGER UNSIGNED NOT NULL, reserved_at DATETIME(6) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; CREATE INDEX reserved_sheets_reservation_id ON reserved_sheets (reservation_id) CREATE INDEX reserved_sheets_event_id_sheet_id_reserved_at ON reserved_sheets (event_id, sheet_id, reserved_at) CREATE INDEX reserved_sheets_user_id ON reserved_sheets (user_id)
初期化処理で既存データをSELECT INSERTで作る
INSERT INTO reserved_sheets (reservation_id, event_id, sheet_id, user_id, reserved_at) SELECT id, event_id, sheet_id, user_id, reserved_at FROM reservations WHERE canceled_at IS NULL ORDER BY event_id, sheet_id, reserved_at
予約済みテーブルを使って高速化/DB負荷を下げる

- 上記のようにcanceled_at IS NULLは全部書き換えられる
- 一番件数の多いreservationsと戦う必要がなくなる
次のようなSQLも
SELECT * FROM reservations WHERE event_id = ? AND sheet_id = ? AND canceled_at IS NULL GROUP BY event_id, sheet_id HAVING reserved_at = MIN(reserved_at)
reserved_sheetsを使うとINDEXが効いたSQLに変更できる
SELECT * FROM reserved_sheets WHERE event_id = ? AND sheet_id = ? GROUP BY event_id, sheet_id
実際にはnajeiraがN+1を対応済みだったので違うSQLで上記は例
中間スコア
13:25時点のスクショが1つだけ手元にあったので記録用にのせておく、振り返るとココからなかなか伸びなかったことがわかる。

最終スコア時の計測結果

- 最後の計測結果は操作がバタバタだったので微妙に結果がスコアと一致してるのか怪しいですが参考までに
- getEventが問題なくなって、予約とキャンセルのロック処理がボトルネックに変わっているのがわかる
決勝の本戦は10月
初優勝したい。
ISUCON本選に出場して9位でした。最高スコアは3位
ISUCON6本選行ってきました

恒例のレゴ

戦ってきましたー

最終スコア

チームにるぽの結果は9位でした。
スコアの推移

最高スコアは31,776点で最高スコアだけなら3位でした。 このスコア出たときはいけるぞ!まだ入賞狙える可能性あるぞ!という感じでしたが、まだ16時だったので、もう少し改善すれば・・という感じでしたが、結果的にはその後バグを混入してしまい1万点台で終わって結果9位でした。
むむむ、惜しかった。
ココまでこれたのもメンバーのおかげ、najeiraが事前に問題予想でチャットとかくるんじゃないかな?ってことで事前に参考実装をgithubにコミットしてて、実際にチャットの実装が使える内容が来てビンゴ!だったのとsoundTrickerがdockerに詳しかったのでインフラ周りはsoundTrickerに完全にお任せという感じになった。
サーバ構成
- isu01
- nginx
- go
- react
- nginx
- isu02
- isu03
- isu04
- go
- react
- isu05
- mysql
- redis
isu01のサーバにてnginxでhttpsを受けて、isu01-04のサーバにhttpで振り分けて処理させる構成にし、isu05はmysqlとredisを入れる形にしました。
感想
賞金は取れなかったけど、ISUCON最高のメンバーで最高に楽しかったなー。 ISUCON6裏話Nightするかもしれないらしいので行こう。
ISUCON6予選突破しました
ISUCON6予選突破
ISUCONというWebアプリケーションのパフォーマンス改善コンテストに参加し、予選突破しました。 やっとですよ。やっと。ISUCON4, ISUCON5と予選敗退していてプライドがズタズタになっていたのでやっと突破できて本当に嬉しいです。
スコアは124,271点(ベストスコアは13万点台)でした。
チーム:にるぽ
appengine ja night(現gcp ja night)つながりでチームを組みました。 @najeira がGo推しだったので言語はGoを選択。私は2年ぶりくらいにgolangを触ることにw
出場チーム数
317チーム中11位でした。
ちょっと気になってコレまでのチーム数を調べたら下記の通り
- ISUCON1 20チーム
- ISUCON2 25チーム
- ISUCON3 74チーム
- ISUCON4 185チーム
- ISUCON5 271チーム
- ISUCON6 317チーム
年々参加チーム数が増えてて強豪揃いの中、ナントカ予選突破できて良かったです。
予選問題
予選の問題は、はてなダイアリーとはてなスターを模したisudaとisutarのhttpサーバが立っていてマイクロサービスアーキテクチャな構成でした。
isudaはキーワードと本文を投稿でき、キーワードが投稿されると全ての投稿本文にあるキーワードがリンクされます。まさにはてなダイアリーみたいな感じです。
予選でやったこと
ざっと変更点を箇条書きすると下記になります。
- isudaとisutarの統合
- インメモリーキャッシュ
- strings.NewReplacerを使うように変更
- 正規表現ライブラリをrubexに変更
- /initializeで最初の1ページはHTML, Regexp, Starのキャッシュを生成
- nginxで静的ファイル配信
- テーブルにindex追加
- entry#updated_at
- star#keyword
ボトルネック
今回の問題はボトルネックがDBではなくキーワードリンクしたHTMLを生成するhtmlifyでした。 DBはuserが500件程度, entryが7000件程度と件数が少なかったためクソな検索でもボトルネックになっていませんでした。 フルスキャンしてるQueryはありましたが最後までそのまま放置し、ボトルネックに集中する戦略にしました。
改修
まずは目に付くマイクロサービスになっているisudaとisutarの統合。httpをやめて直接SQLを発行かつインメモリキャッシュできるように変更。ココはサクッと @soundTricker が行いました。振り返ってみるとあとはひたすらインメモリーキャッシュですね。htmlifyしたHTML、Regexpのインスタンス、Star、Spam、Userはテーブル全件をキャッシュしました。
並行に作業を進めていたのでどれが劇的にスコアに影響を与えたのか言い難いですが、終盤スコアがあがっていったのは下記の変更を入れ始めてからだったと思います。
- htmlifyの中で正規表現オブジェクトを毎回作るのではなくhtmlifyの外で正規表現オブジェクトを作る
- HTMLと正規表現オブジェクトをキャッシュする
- strings.NewReplacerの利用
- 正規表現ライブラリをrubexに変更
- 終盤は正規表現ライブラリを変更したら2万点くらい上がりました。
司令塔 najeira
@najeira が本当に素晴らしい仕事をしてくれてインフラとアプリの改修、ボトルネックの計測という全ての面で大活躍。「そこって遅いの?本当にボトルネックなの?」と問いかけどこを修正するべきかを指揮し、全てが的確でした。@najeira がhtmlifyの対応をしている時にじゃ他のところやるかーってなっていたのを「いや三人でココをナントカするべき」という判断を下したのが印象深いです。
また、事前に下記のgoライブラリを用意してました。
- パフォーマンス計測
- デバッグプリント
- 型変換
ボトルネックを調査するためにmeasureで計測
まず最初にmeasureを埋め込み/statsにアクセスすると計測結果を確認できるようにし、/stats_resetで計測結果をクリアできるように準備します。その後ベンチマークを走らせて/statsのurlを叩けば遅い箇所が一目瞭然になるようにしていました。計測結果はGoogle Spreadsheetで共有し @najeira が計測した結果を元に次にどこを修正すべきかの道筋が立てられたのは本当に大きいです。
この辺りは @najeira とは2回目のISUCON参加ということもあり、事前に考えて準備し工夫していた効果が出て良かったです。
debugとconv
私が普段golang触っていないこともあり、デバッグするためのライブラリdebugを作ってもらいました。とりかくdebug.Printしまくってポカミスを減らせました。debug.Printは実行時に実行されたファイル名とファイルの行数と引数の値を確認できるライブラリです。事前に即席で作ってもらいました。
golangに慣れてないせいで数値から文字列、文字列から数値変換など簡単な事もさっと出てこないためconvを作ってもらいました。Stringにしたかったらconv.Stringだし、Intにしたかったらconv.Int(s)すれば済みます。
また、/testというハンドラを用意しそこでデバッグするようにしてました。
r.HandleFunc("/test", myHandler(testHandler))
func testHandler(w http.ResponseWriter, r *http.Request) { debug.Print("== Call /test") responseText := conv.String("test") // ココでfuncのコードを動作確認 w.WriteHeader(200) responseText = fmt.Sprintf("%s", responseText) fmt.Fprintf(w, responseText) }
あとは起動してcurl http://localhost:5000/testする感じです
予習
事前に一度三人で集まってpixivの社内ISUCONの課題を解きました。素振り重要です!matsuuさんのおかげで初azureでもさっと課題に取り組めました。感謝。 matsuuさん毎年いつもありがとうございます。
- https://github.com/catatsuy/private-isu
- https://github.com/matsuu/azure-isucon-templates/tree/master/pixiv-isucon2016
環境構築
サーバ起動したらansibleで全員ssh入れるようにし主要なツールは入れられるようにしてました。
デプロイ
fabricを使いました。fabric使ったこと無かったけど便利ですね。簡単で軽量で。 これを使ってgoのビルド、デプロイやnginxの設定ファイルの配布やnginxの再起動など全てをfabコマンドで行えるようにしてました。
競技終了前のチェック
大事ですね。この時間ずっとドキドキしていました。17時までに修正をやめて再起動テストを行う時間を作ろうというのは最初から話をしていたので、大きな修正は16:50頃には終わっていました。そこからはずっと再起動テストを行いスコアがfailしないこと、レギュレーションを読み直して大丈夫だよね?ってのを確認してました。
最後に
本当にメンバーに救われました。@najeira, @soundTricker のおかげで本選に出場できました。メンバーには感謝です。 私はココをこうすればいいんじゃないの?とは言えてもgolangだと書き方がわからなくってみたいなのが多々あり、アイデアしか出せない場面もあったり本選は足をひっぱらないようにgo力高めておきます。
本選も優勝目指して頑張るぞい。
Amethystを使い始めてSpacesを見直してTotalSpaces2を入れた
MacでSpacesはVMWareでWindowsを起動するときくらいしか使ってなかったんですが、Amethystというタイル型ウィンドウマネージャを入れたことでより良いSpaces環境が欲しくなってTotalSpaces2を導入した。
TotalSpaces2の気に入ったところ
特定のアプリケーションは必ず同じスペースで起動できる
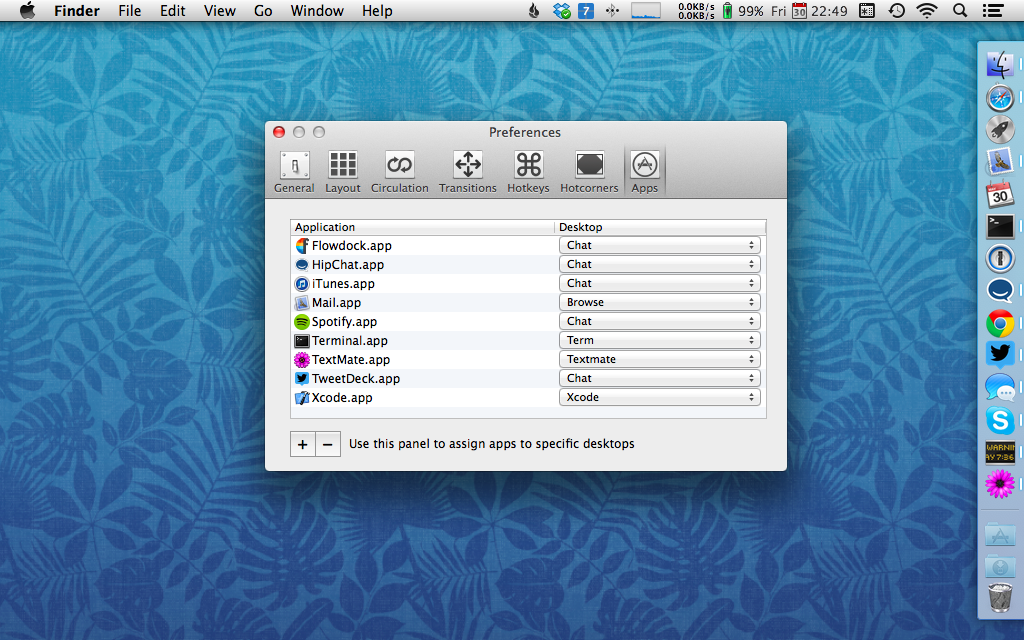
Amethystでchromeは左右二画面で見たいけど、エディタやターミナルは常に最大化した一画面で見たかったので用途毎にスペースを変更し、スペース毎にAmethystのLayout設定を変更するようにした
スペース移動時に発生するアニメーション機能をオフにできる
もっとかっこよく出来る機能があるのですが、完全にオフにする機能があってソレが快適です
スペースにショートカットキーを指定できる
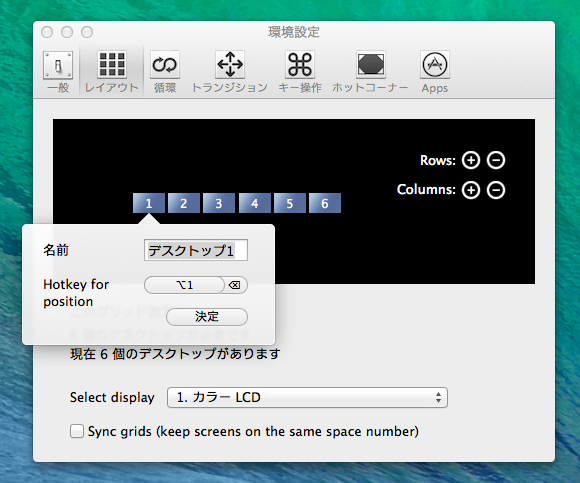
Chromeでよくcommand+数字キーのショートカットを多用するのでそれと同じようにスペースも変更可能にした
rubyでArray#find, detectを使い分ける
detectメソッドは、findの別名です。
今までfindをよく使ってましたが、ActiveRecordを使っているところではActiveRecordのfindと区別するためにdetectを使おうってメンバーが話しててそうだなと思った。